最近看了 Cognition 的一篇文章:Don’t Build Multi-Agents。
我比较认同它的核心判断,不过重点不是“多 agent 永远不行”,而是一个更现实的问题:
在今天这个阶段,多 agent 最大的问题不是不会分工,而是共享不了稳定、完整的上下文。
简单说就是:
- 看起来大家都在做事
- 实际上大家理解的不是同一件事
- 最后再把这些结果拼起来,系统就开始变脆
所以很多 agent demo 看起来很热闹,但一上复杂任务就容易散架。
为什么看起来可行
多 agent 这件事,第一眼看上去是合理的。
一个大任务拆成多个子任务,然后让不同 agent 并行去做,最后再汇总结果。这个思路在人的协作里也成立,在分布式系统里也成立,所以它天然很有吸引力。
例如一个“做一个 Flappy Bird 克隆”的任务,你很容易会这样拆:
- 一个 agent 负责背景和障碍物
- 一个 agent 负责小鸟和交互
- 最后一个 agent 负责把它们合起来
大概就是这样:
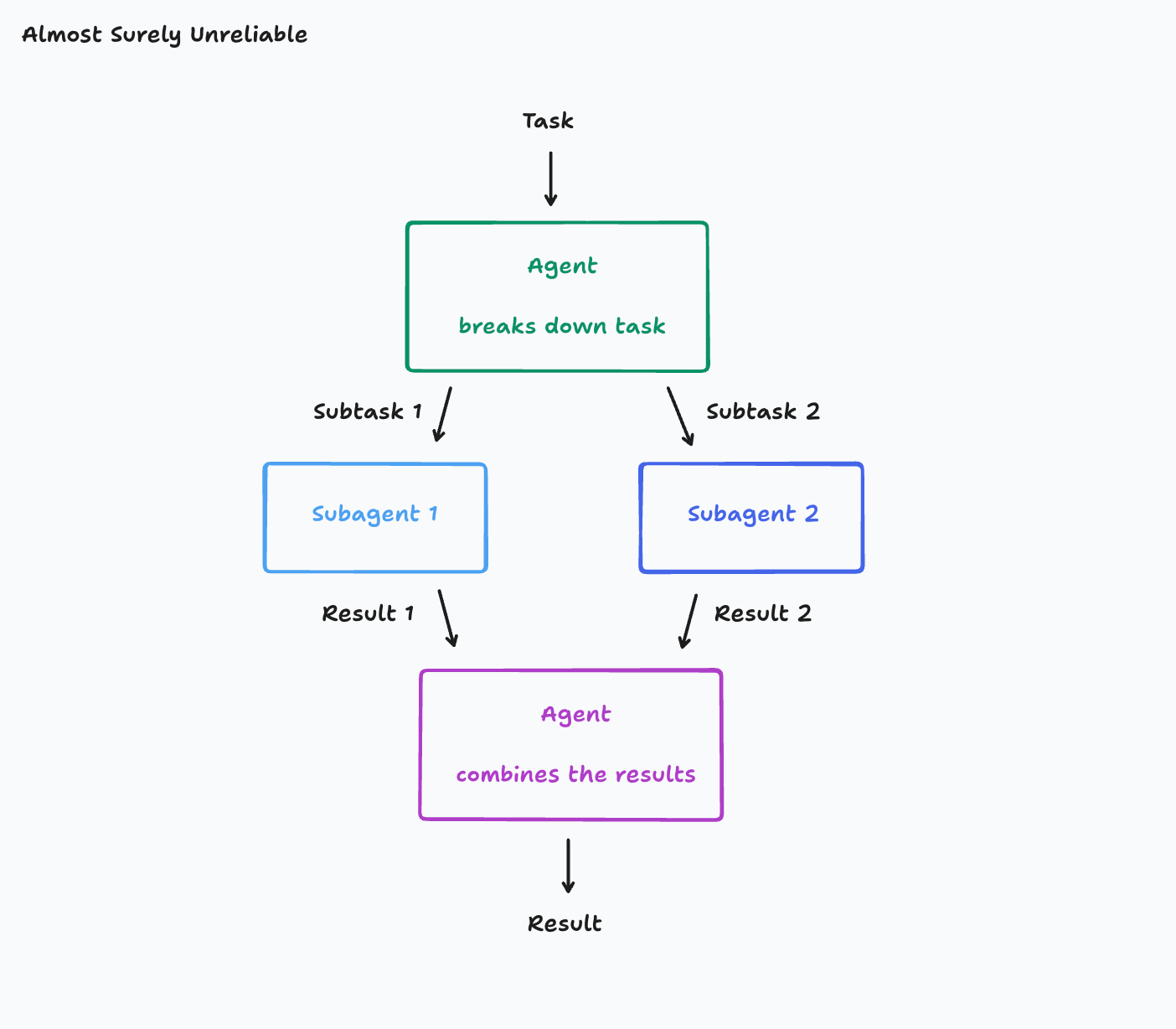
问题在于,这种结构虽然“像是在提效”,但它对前提条件要求很高。
你默认每个 agent 都准确理解了任务。
你默认它们对风格、边界、目标、约束的理解是一致的。
你默认最后那个汇总 agent 有能力把前面所有偏差都修平。
可实际情况往往不是这样。一个 agent 理解成了马里奥风格的背景,另一个 agent 做出来的小鸟像别的游戏素材。单看都不算全错,但拼起来就是不对。
问题不在于单个 agent 能力差,而是任务一旦拆开,误解也会被拆开,而且会互相放大。
第一个问题
很多人第一反应会觉得,那就把原始任务也传给每个子 agent 就好了。
听上去合理,但工程上往往没这么简单。
因为真实系统里的上下文,从来不只是用户最开始那一句需求。
它通常还包括:
- 前面几轮对话里澄清过的细节
- agent 通过工具调用拿到的信息
- 中途已经做出的设计决策
- 某些没明说但已经默认成立的约束
所以你给子 agent 的,很多时候不是完整上下文,而是主 agent 处理过的一段“任务摘要”。而摘要本身就会丢信息。
原文在这里给出的第一个原则,我觉得很值得记住:
尽量共享完整上下文,最好共享完整 trace,而不只是某几条消息。
图是这样的:
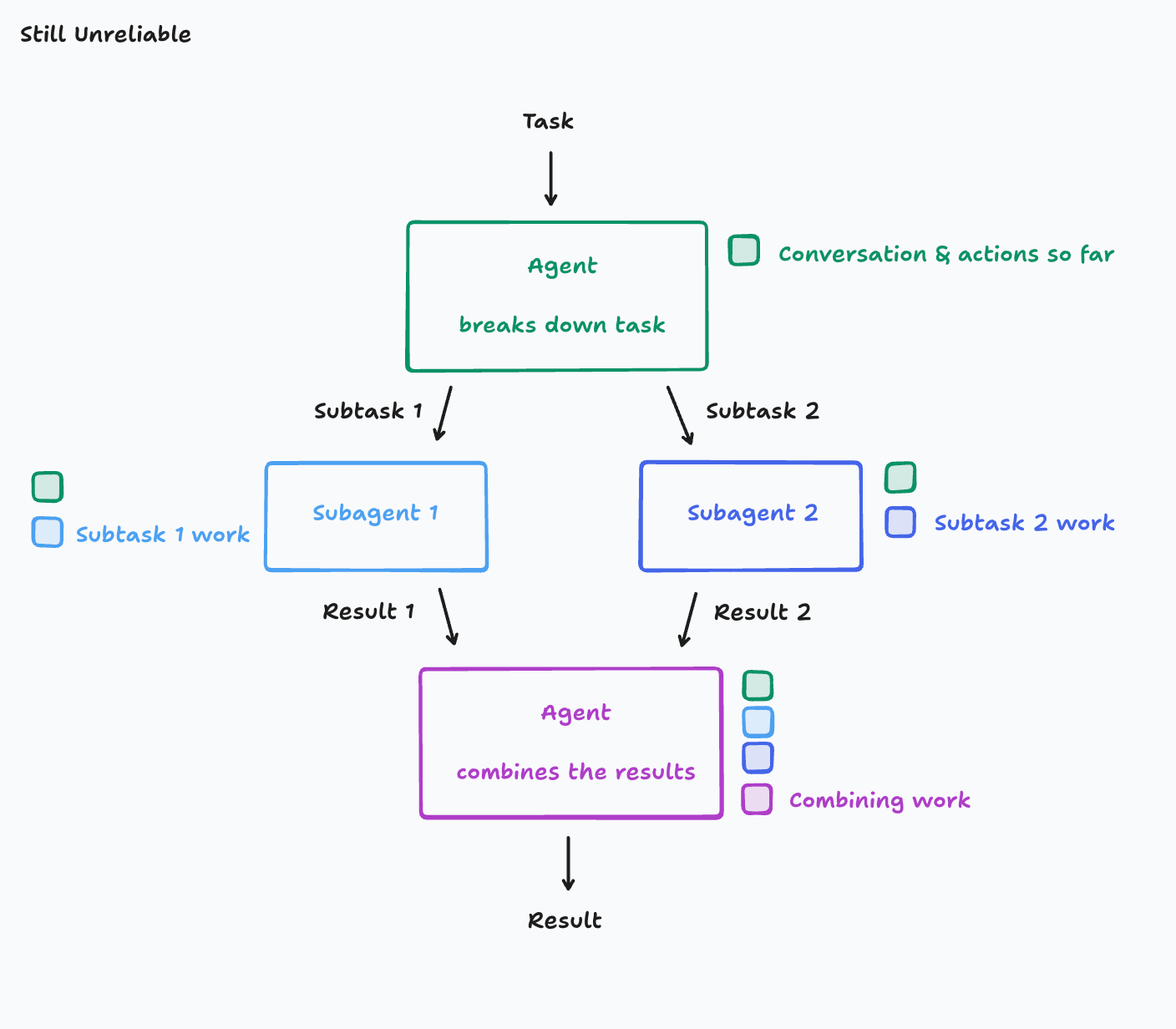
这个原则说白了就是一句话:不要以为传了一段说明,就等于传递了原本的理解过程。
对 agent 来说,很多关键决策并不写在最终消息里,而是藏在前面的推理、工具调用和取舍过程里。少掉这些,子 agent 拿到的就只是一个“差不多”的版本。
第二个问题
但就算已经尽量把上下文共享出去了,问题也不一定就没了。
很多决定,并不是显式写出来的,而是通过动作本身被做掉了。
比如一个 agent 开始写某种 UI 结构,选了某种代码组织方式,或者默认了某个 API 契约。它虽然没专门说“我决定这样做”,但这个决定已经发生了。
这时候如果另一个 agent 在并行做别的部分,并基于另一套假设往前推进,最后冲突几乎是必然的。
原文里把这个问题总结成一句话,我觉得挺准:
Actions carry implicit decisions.
也就是:
动作会携带隐式决策。
这点很像真实工程开发。两个工程师如果没有同步设计约束,分别写自己那部分代码,最后合并时经常会发现:
- 命名体系不一致
- 数据结构假设不一致
- 错误处理方式不一致
- UI 风格不一致
- 依赖边界不一致
这还不是因为谁写得差,而是因为每个人在推进时,都顺手做了一些本该共享的决定。
人类团队还能靠开会、评审、文档来补这一层,但 agent 现在在这方面还差得远。
为什么我更倾向单线程
如果按上面这个思路往下看,那我还是会更倾向单线程。在很多真正要求可靠性的任务里,单线程 agent 反而更稳。
结构很简单,就是一条连续上下文往前走:
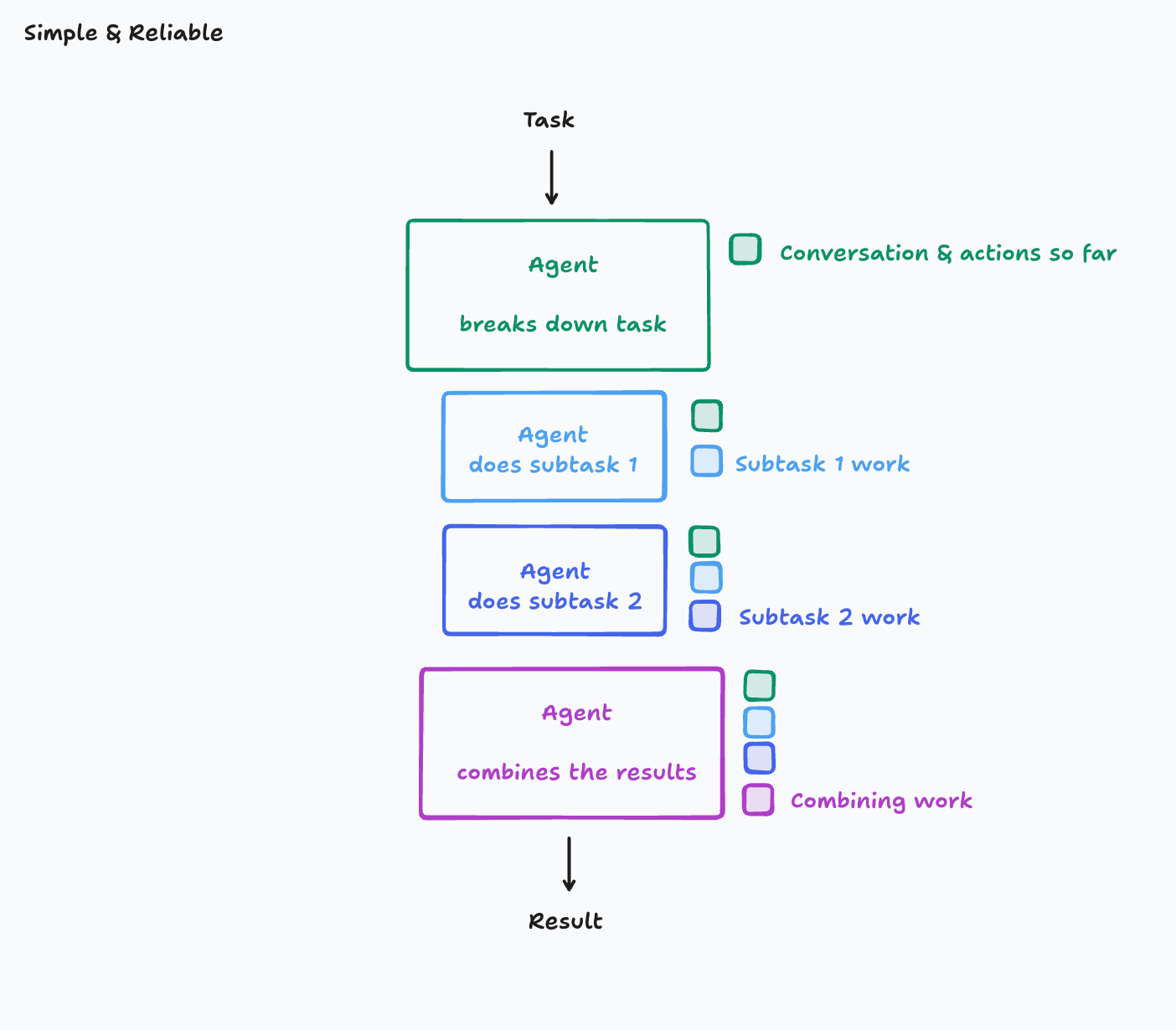
它不炫,也没有“多个 agent 同时工作”的观感优势。但它有一个很实际的优点:
上下文是连续的,决策链路也是连续的。
你不需要担心某个子 agent 少拿了一段背景。
也不需要担心另一个子 agent 在你看不到的地方做了冲突决策。
很多时候,系统的稳定性不是来自“分工更细”,而是来自“决策没有断层”。
在 agent 系统里,可靠性通常先于并行度。如果连一致性都保不住,那么并行只是在更快地产生冲突。
单线程的问题在哪
当然,单线程 agent 也不是没有问题。最直接的还是 context window。
任务一长、步骤一多、历史一累积,就很容易顶到上下文上限。
这里的图也很直观:
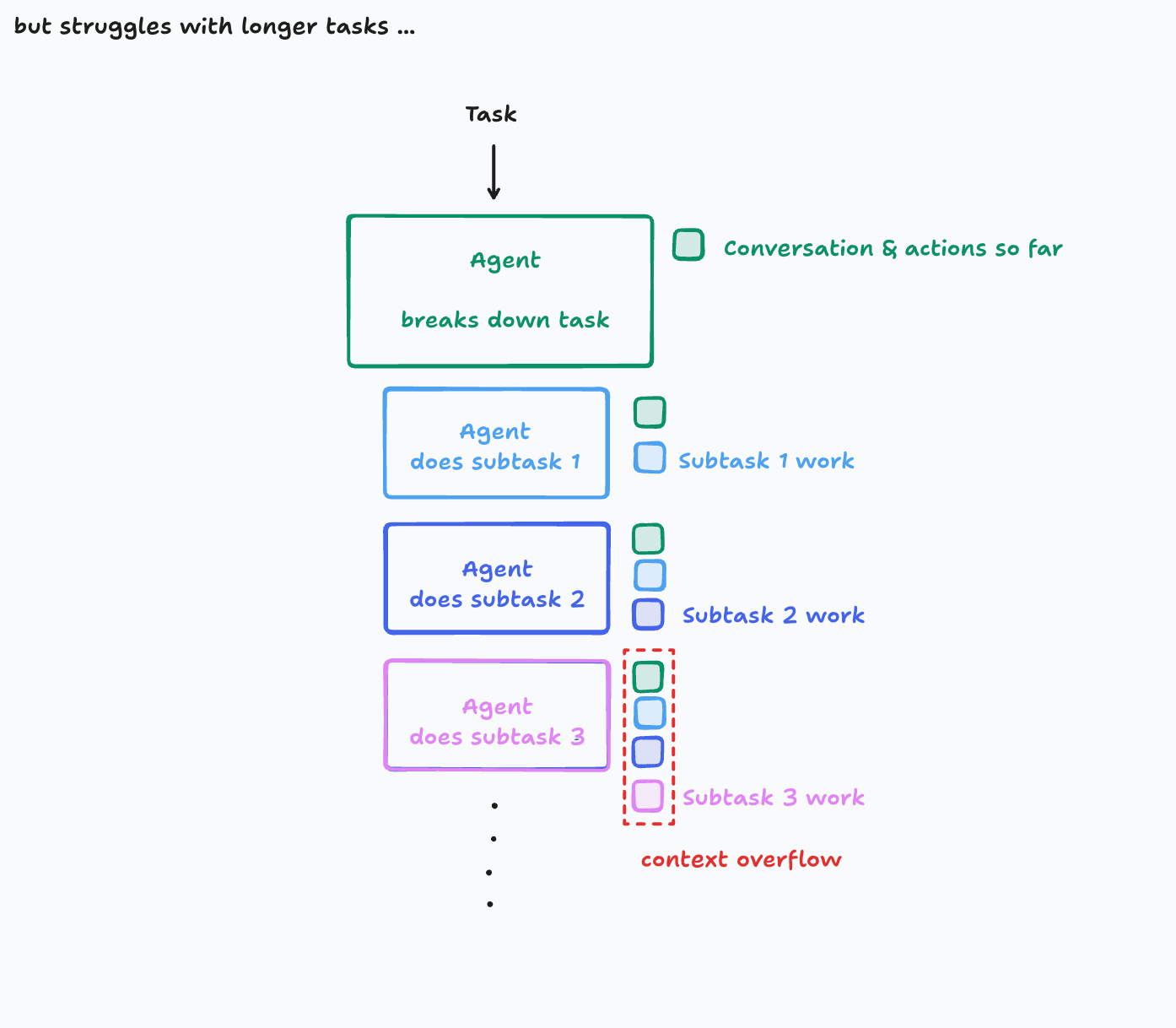
这个问题在短任务里不明显,但在长周期任务里会很快出现。比如:
- 连续多轮的编码任务
- 大仓库里的渐进式修改
- 需要长时间维护状态的自动化工作流
这时候你会发现,单线程虽然稳,但它也会“记不住”。
所以真正的问题并不是“单 agent 还是多 agent”,而是:
当上下文变长之后,系统怎么继续保住关键决策。
还有什么办法
我觉得这篇文章比较有价值的地方,不只是批评多 agent,而是也给了一个方向:
不要急着把决策拆给多个并行 agent,先想办法把已有决策压缩好、继承好。
图示如下:
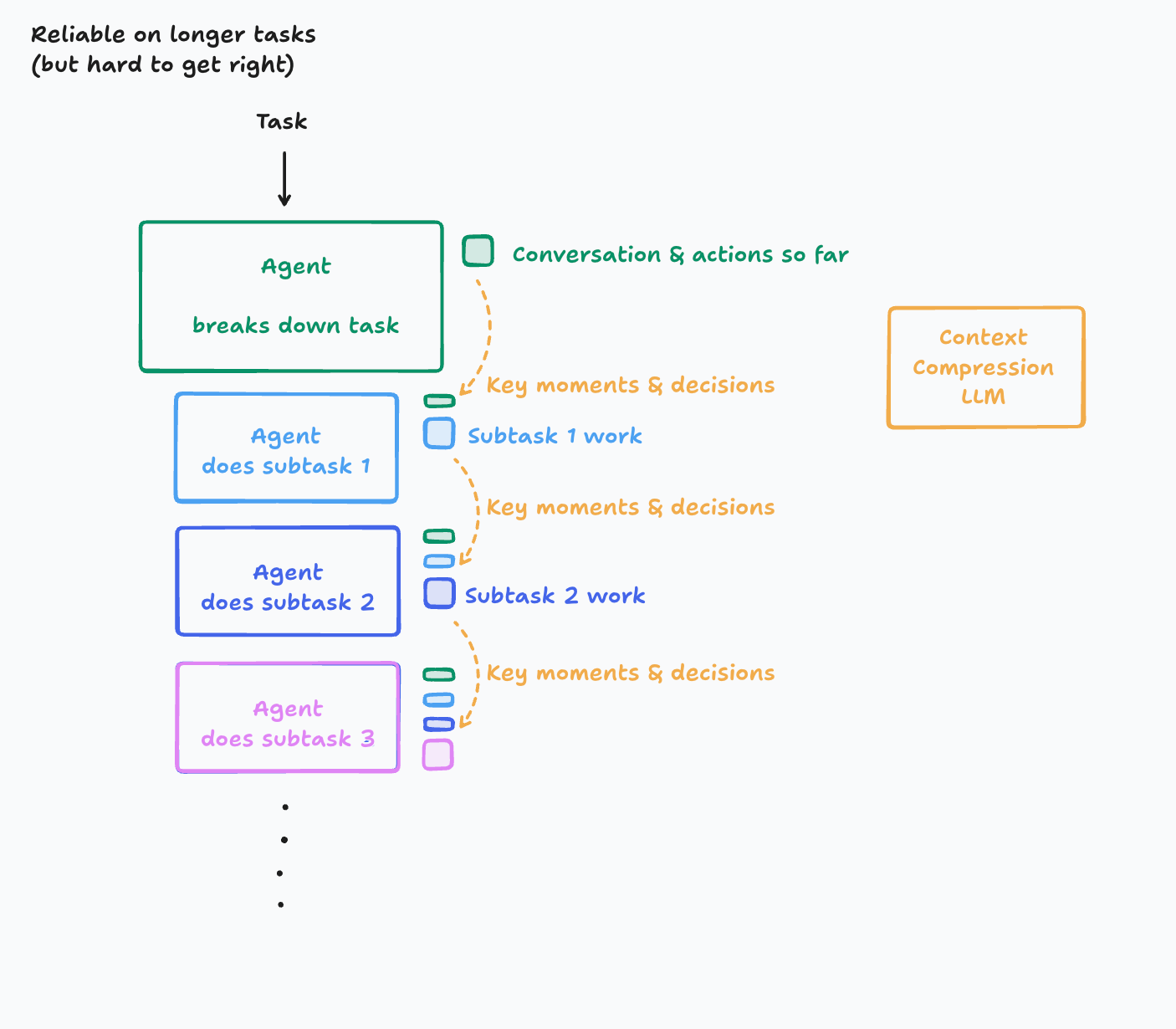
这里的核心思想是增加一层“上下文压缩”能力,把长历史里的关键事件、关键约束、关键决策提炼出来,再继续传给后续步骤。
这个方向的好处是,它解决的是更本质的问题:
- 什么信息必须被保留
- 什么决策会影响后续动作
- 什么上下文不能在压缩时丢掉
这件事其实比“把任务拆成三份并行跑”更难,但也更接近真实可用系统要面对的问题。
因为真正让 agent 失控的,很多时候不是模型不会写,而是系统没有把过去做过的判断保留下来。
为什么我认同这个说法
因为这件事和普通工程经验其实是对得上的。
我们做系统设计时,通常不会默认“模块越多越高级”。相反,大家会很警惕下面这些问题:
- 状态同步成本
- 跨模块沟通损耗
- 决策边界不清
- 接口语义漂移
- 最后集成阶段的隐性冲突
多 agent 的问题,本质上没有脱离这些经典工程问题。只是以前这些问题发生在人和服务之间,现在发生在 agent 和 agent 之间。
所以我现在更倾向于把 agent 系统理解成这样:
- 真正重要的是 context engineering
- 并行只是可选优化,不是默认答案
- 如果共享不了完整上下文,就不要过早把决策拆开
总结
最后简单收一下:
- 多 agent 最大的问题,不是调度,而是上下文共享不完整
- 真正危险的,不只是消息传丢了,而是隐式决策彼此冲突
- 在今天这个阶段,单线程 agent 往往比并行多 agent 更稳
- 当单线程开始受限时,更优先该补的是上下文压缩与继承能力,而不是贸然加更多 agent
这不意味着多 agent 没有未来。
而是至少在现在,很多系统还没把“共享理解”这件事解决好,就已经开始追求“并行执行”了。从工程角度看,这个顺序大概率是反的。
先把一致性问题解决,再谈并行,通常会稳很多。