关于赛题
天池大赛又开始啦,不过这回改名了,叫“云原生编程挑战赛”了,这回有三个题目,我选择了其中的第二个项目:实现一个柔性集群调度机制
2021第二届云原生编程挑战赛2:实现一个柔性集群调度机制-天池大赛-阿里云天池
题目内容
Apache Dubbo 作为一款可拓展性极高的 RPC 框架,支持高度自定义化的集群调度机制,本次比赛要求参赛者基于 Dubbo 提供的集群调度自定义化能力,辅以调用过滤链机制、自定义负载均衡机制等功能,设计一种柔性调度机制。
一般来说,集群大规模部署可能会遇到这些问题:
首先,由于网络波动或者是机器维护等客观原因,导致部分节点阶段性地不可用。
其次,得益于虚拟化机制,当今云计算的资源利用率可以大幅提高,这会带来诸如虚拟机之间相互争用宿主机资源,部分虚拟机会因此性能显著下降。
而集群的柔性调度正是指 Dubbo 能够从全局的角度合理分配请求,达到集群的自适应。具体来说使消费者能够快速地感知服务端节点性能的随机变化,通过调节发送往不同服务端节点的请求数比例分配变得更加合理,让 Dubbo 即使遇到集群大规模部署带来的问题,也可以提供最优的性能。
成绩
通过初版的基于窗口的动态监测生产端内存使用率和耗时策略。
我创建的小队,取得A榜(提供日志可调试)60名的成绩。
最终成绩定位在B榜17名。
证书如下:

解题思路和方向
搭建环境
首先便是搭建项目了,这一部分其实是体力活。
在code.aliyun.com fork 出一份provider-consumer 并clone到本地,用于开发与调试。
clone下来 internal-service项目,internal-service项目依赖provider-consumer提供的调度策略,它默认提供了一个随机的策略。
按照教程运行 internal-service,打开浏览器 http://localhost:8087/call ,显示OK即表示配置成功。
使用压测工具来检验性能wrk -t4 -c1024 -d90s -T5 –script=./wrk.lua –latency http://localhost:8087/invoke
分析项目
首先便是internal-service了,它被分为三个模块,其中service-provider是provider的实现代码,按照题目原文的: “接口的响应时间符合负指数分布”,我们找到了对应的模拟耗时的代码。
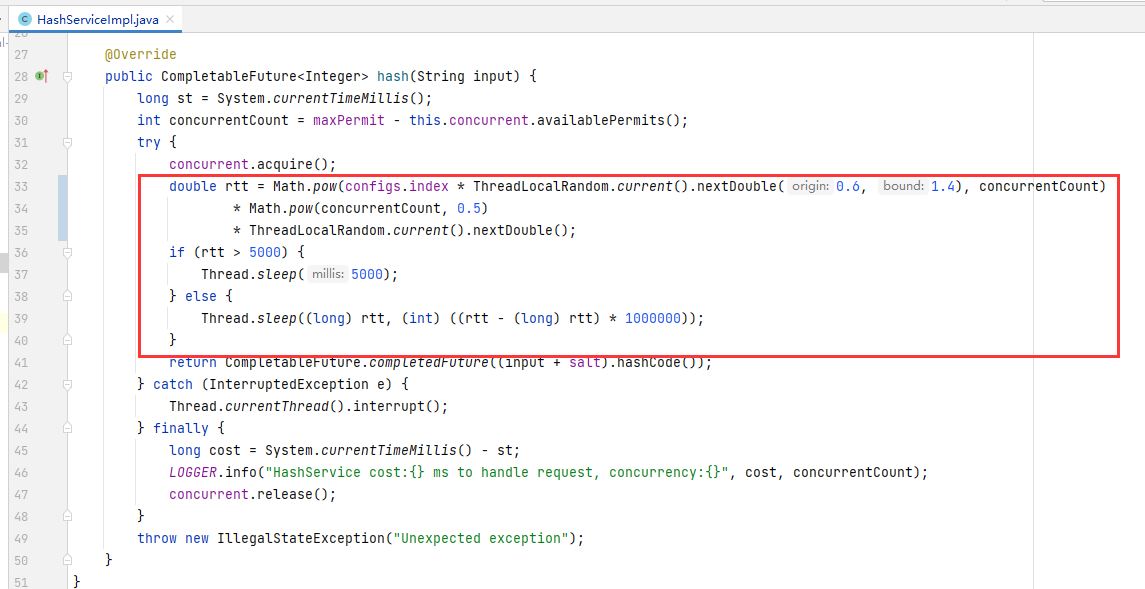
这是什么的效果呢,rtt耗时会根据当前本进程的并发量和index作相应变化。
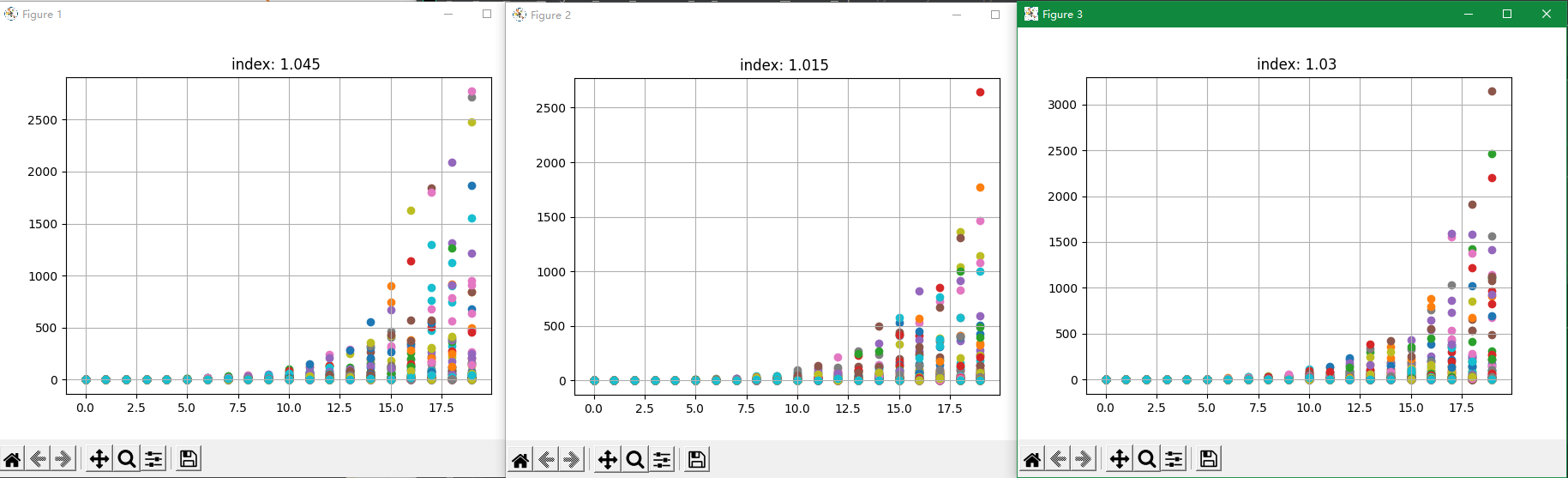
这张图是模拟的不同index值时,rtt跟并发量值的关系(每个并发量值重复十次)。
当然,耗时是随时变化的,但是也是平滑变化的(这里也就假设了并发量在短时间内不会变化得太明显)。
所以,我们可以通过最近N次请求的实际耗时情况来预测这一次请求的耗时值。
基于遗忘窗口的平均耗时统计
由于是自制的遗忘窗口,我这里便创建了一个基于内存的ForgetfulCache,其原理时只保存rememberSize的数据,不断移动index以便重复覆盖内部数据
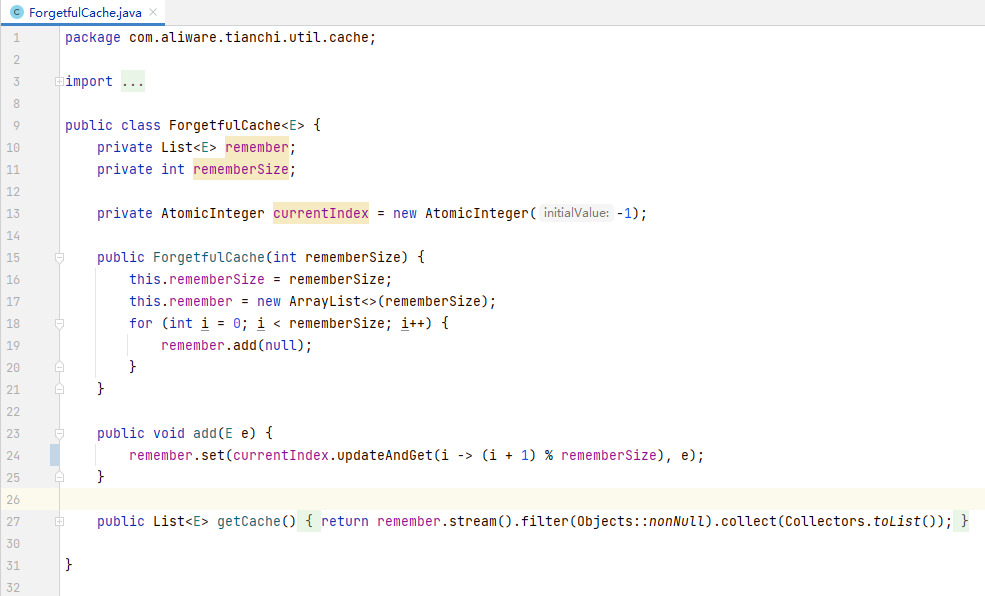
接着便是按照dubbo提供的ActiveLimitFilter,以及 RpcStatus 的实现方式,自定义一遍ForgetfulRpcStatus.
ActiveLimitFilter(from dubbo):
1 | public class ActiveLimitFilter implements Filter, Filter.Listener { |
TestClientFilter: (DIY)
1 | public class TestClientFilter implements Filter, BaseFilter.Listener { |
ForgetfulRpcStatus 关键代码:
1 | private static class Data { |
现在,我们通过ForgetfulRpcStatus就可以拿到过去一定”次数“下的耗时了,只需要在UserClusterInvoker#doInvoke时,在invoker.invoke前给上下文信息的TIMEOUT_KEY填充下刚才获取到的历史平均耗时即可。
1 | double averageElapsed = ForgetfulRpcStatus.getStatus(url, methodName).getAverageElapsed(); |
瓶颈位置
通过讲打点日志汇总,并填充到kibana.(因为这个项目时跟时间序列密切相关的,而且成绩统计是会剔除预热阶段,为了能够找到瓶颈点,特地搭了这个kibana环境)
因为日志分析的截图有部分缺失,所以在写这篇文章的现在,我提供的部分现象跟分析图片会出现部分图文不符的情况。
- 请求成功率低,后期基本都是在0.5-0.6,以20880最为明显。
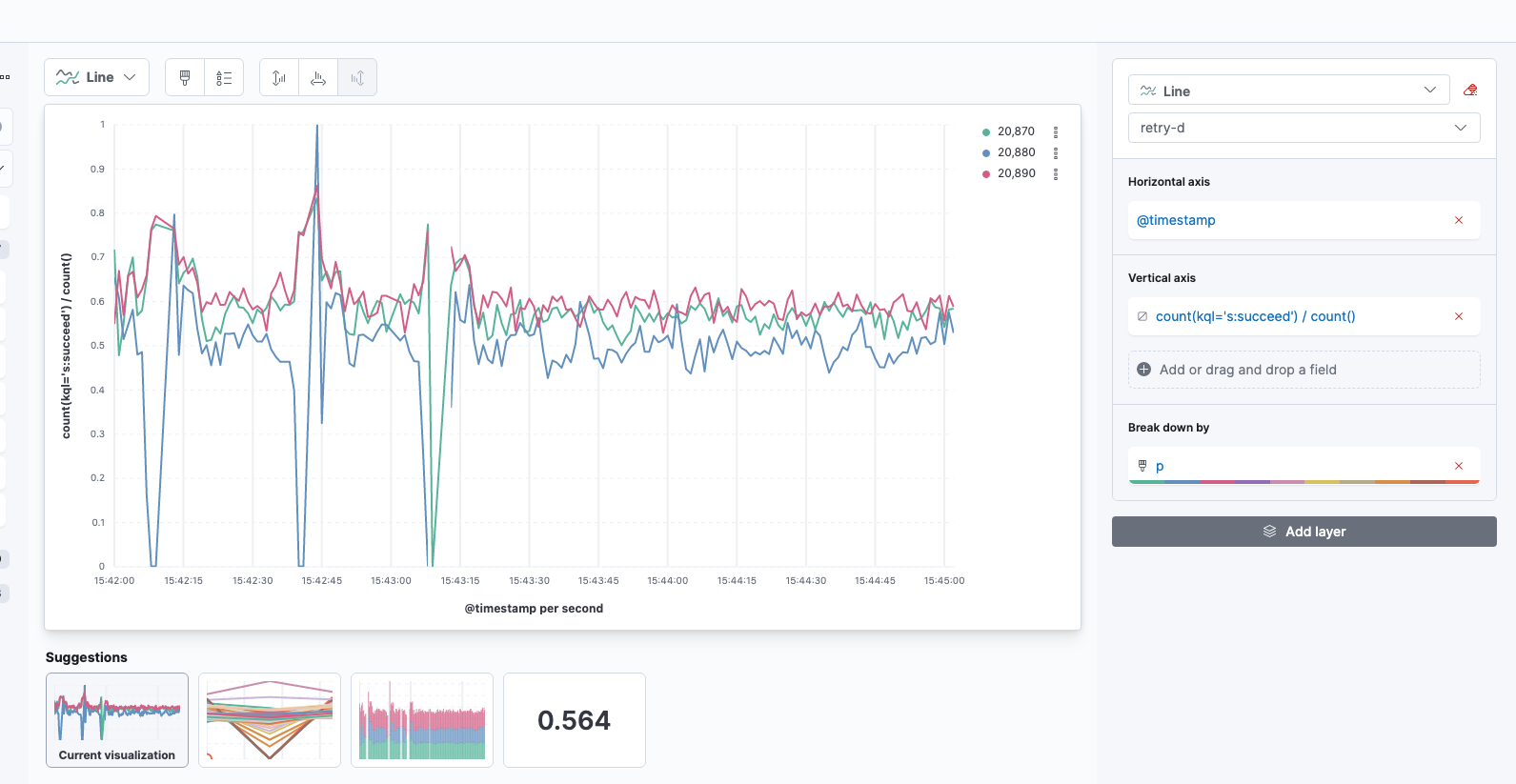
- 耗时统计前期会时高预期(符合逻辑)。到达稳定时,各节点的预计耗时在3-10ms
- 失败率会随着时间不断得缓慢增加(无配图)
针对成功率的优化
请求成功率偏低,说明预测时间被压缩得太过明显。
失败率会逐步增加,也就是说在后续得预测中,会预测得越来越差。这个得原因是失败的任务最终耗时会是预测值,那么这个预测值会只降不增(因为历史耗时时间永远不会大于前N次的预测值)
通过给失败任务添加惩罚机制,即失败任务的耗时会记录到更高的值,能够解决。
也即在ForgetfulRpcStatus.data 中:
1 | public Data(long elapsed, boolean succeeded, long time) { |
到这一步时,这一部分代码已经能使三分钟总吞吐量达到200w,单次请求成功率在 0.8左右。
但由于提交次数太多,已经找不到可以佐证的具体成绩跟相关日志了。
使用EwmaBasedLoadBalance,并在算法中考虑并发量
我们还可以做更多吗,这是可以的。
通过一些统计学知识的补充,我意识到我们可以使用Ewma来完成耗时统计,并在算法中考虑并发量。
思路来自于https://github.com/apache/dubbo-spi-extensions/pull/68,我的实现里把对应逻辑搬运到了EwmaRpcStatus
I am disappointment with shortestResponseLoadBalance,though it is better than others in latency spike. However, it’s slow for it depends on average.I am looking forwad to a sensitive loadbance.
PeakEwmaLoadBalance is designed to converge quickly when encountering slow endpoints.
It is quick to react to latency spikes recovering only cautiously.Peak EWMA takes history into account,so that slow behavior is penalized relative to the supplieddecayTime.
核心代码:
1 | private static void endCount(EwmaRpcStatus status, long elapsed, boolean succeeded) { |
到这里,便是形成我的最高分数的策略了,基于EwmaRpcStatus 和 ForgetfulRpcStatus(with simple punish)实现的EwmaBasedLoadBalance和耗时预计。
很奇怪的点是我尝试使用EwmaRpcStatus提供耗时预计时,并没有得到很好的成绩,由于当时时间的原因,便没有再尝试了。这里是比较遗憾的点。
做了但是收效甚微的工作
- 基于CPU使用率和虚拟内存使用率(注意这里时虚拟内存,因为实验环境是在Docker上的)的LoadBalance。
- 单纯以并发量作为权重的LoadBalance。
- 以单位时间内成功率作为权重的LoadBalance。
- 在TestClientFilter加入重试机制,优点是提高成功率,缺点是这会导致gateway的阻塞,降低gateway的吞吐量。