感知机
感知器(英语:Perceptron)是Frank Rosenblatt在1957年就职于康奈尔航空实验室(Cornell Aeronautical Laboratory)时所发明的一种人工神经网络。它是一种二元线性分类器。
多层感知器(Multilayer Perceptron,缩写MLP)是感知器的推广。在模式识别的领域中算是标准监督学习算法,并在计算神经学及并行分布式处理领域中,持续成为被研究的课题。MLP已被证明是一种通用的函数近似方法,可以被用来拟合复杂的函数,或解决分类问题。
why Deep
大家都在提 “深度神经网络”,那么,神经网络就一定是要“深度”(deep)的吗?我们常用的 Logistic regression 就是单个的感知器,没有多层,也能对简单数据进行很好的预测(当然它还需要选择不同的function set)。现在神经网络基本都是 deep 的,即包含多个隐含层。Why?
通用近似定理
universality approximation theorem(通用近似定理)提出: 任何连续的函数 $f: \mathbb{R}^{N} \rightarrow \mathbb{R}^{M}$ 都可以用只有一个隐含层的神经网络表示。(隐含层神经元足够多)
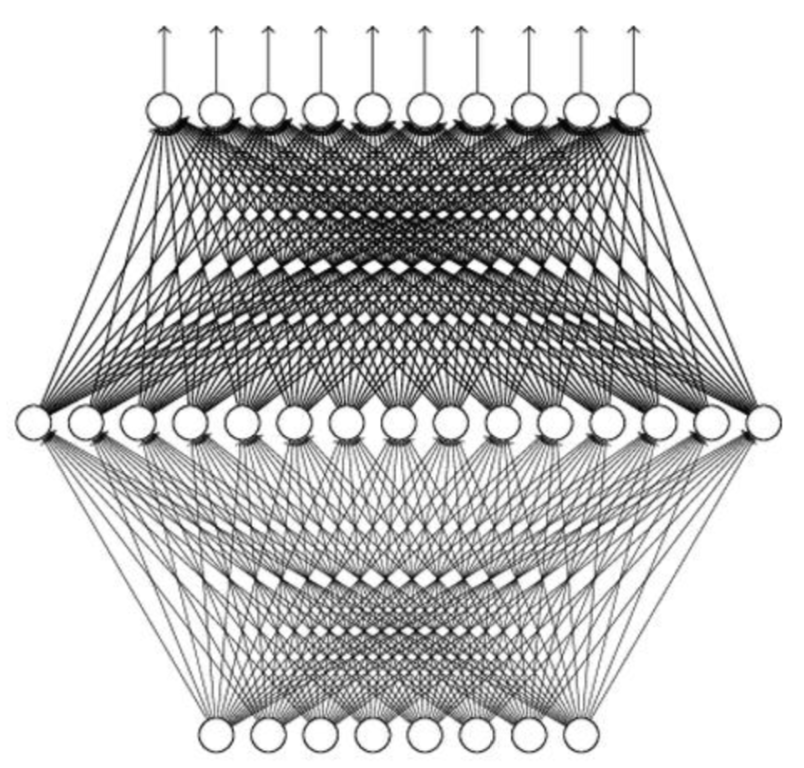
一个神经网络可以看成是一个从输入到输出的映射,那么既然仅含一个隐含层的神经网络可以表示任何连续的函数,为什么还要多个隐含层的神经网络?
尝试实践
实践出真知,为何不尝试一下,自己创建一些数据,验证一下是不是“深度”模型效果更好。
导入依赖
1 | import numpy as np |
创建数据并分类
1 | def generated(): |
随机生成X的二维坐标, 并使用一个较为复杂的function对X进行二分类,生成对应的y, ($y \subseteq \left { 0, 1 \right }$)。
展示分布
1 | def show(title, X, y): |
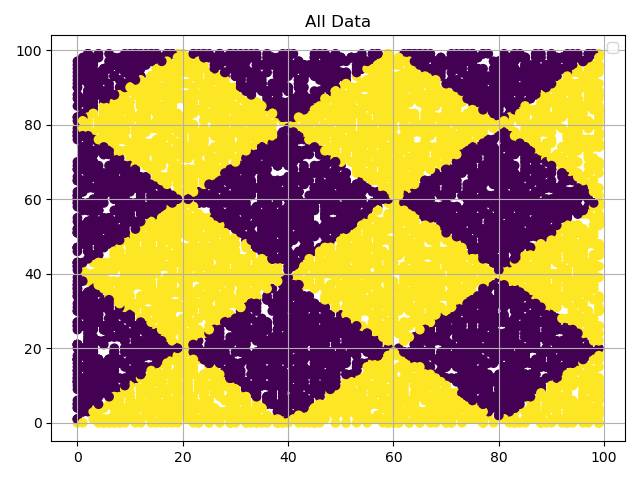
通过展示数据分布,我们可以看出,刚刚的复杂function,是用重复的菱形结构将数据划分成两个分类。
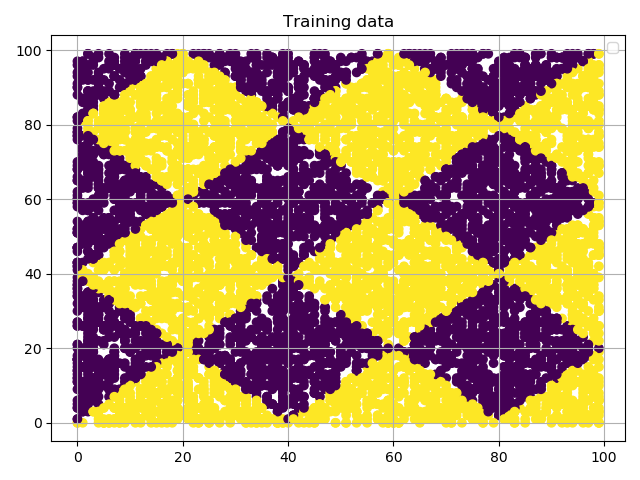
切分训练数据和测试数据
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
使用各种工具方法,编程成本急剧下降。
使用“Deep”模型
1 | # deep模型 |
使用MLPClassifier,并配置对应的隐藏层size,其他参数如activation, alpha均使用默认。
训练完完毕后验证正确率,正确率0.86,通过图可以看出,这个模型预测的分类在边界选择上已经很接近正确答案了。
使用“fat”模型
1 | # fat模型 |
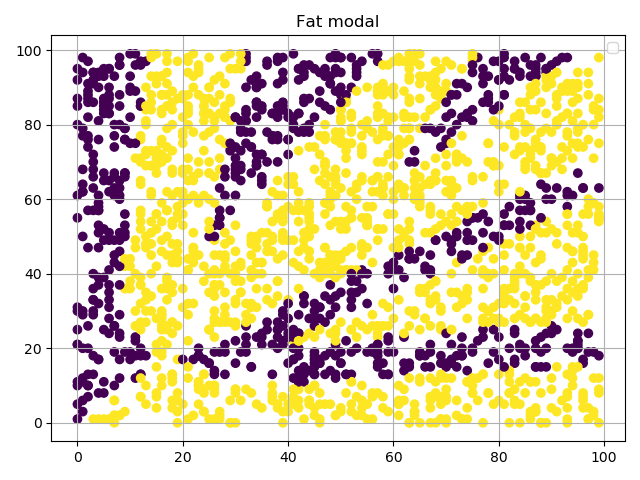
同样使用MLPClassifier,并配置对应的隐藏层size,其他参数如activation, alpha均使用默认。
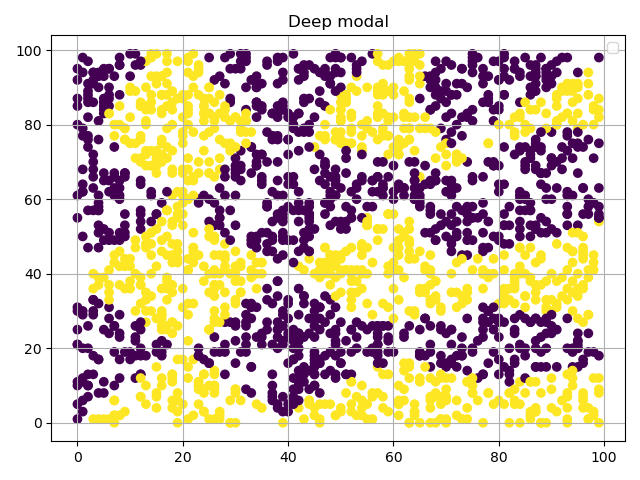
正确率0.69,说实话比我本来预计的分数要高一些。但是通过图就可以看出,这个模型,分明就是在瞎分类。
实践结论
只有一个隐藏层的感知机模型,即使占用1000个感知机,也无法fit到只复杂了一点的function。在这个场景下,他的效果远远不如只有三个隐藏层,每层40个感知机的模型。
合理的解释
李宏毅教授在他的机器学习视频中,提出一种叫做 Modularization(模块化)的解释。在多层神经网络中,第一个隐含层学习到的特征会是最简单的,之后每个隐含层使用前一层得到的特征进行学习,所学到的特征变得越来越复杂。
在比较深度神经网络和仅含一个隐含层神经网络的效果时,需要控制两个网络的 trainable 参数数量相同,不然没有可比性。李宏毅教授在他的机器学习视频中举例,相同参数数量下,deep 表现更好;这也就意味着,达到相同的效果,deep 的参数会更少。
不否认,理论上仅含一个隐含层的神经网络完全可以实现深度神经网络的效果,但是训练难度要大于深度神经网络。
实际上,在深度神经网络中,一个隐含层包含的神经元也不少了,比如 AlexNet 和 VGG-16 最后全连接层的 4096 个神经元。在 deep 的同时,fat 也不是说不需要,只是没有像只用一层隐含层那么极端,每个隐含层神经元的个数也是我们需要调节的超参数之一。
实践番外
貌似这个场景更适合使用KNN模型,所以尝试上代码:(其实这是不合适的,毕竟KNN是适用于少量数据集的预测)
1 | from sklearn.neighbors import KNeighborsClassifier |
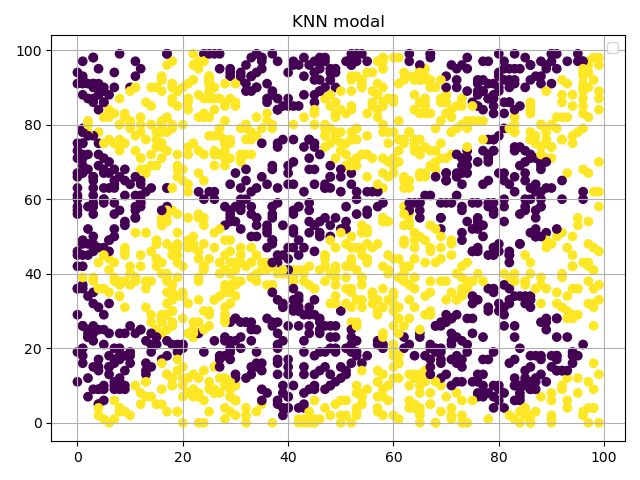
不得不说,KNN还是强的,效果显著。0.97的正确率足以艳压群芳。
推荐
李宏毅机器学习 【优秀的宝可梦训练师,幽默的教学风格】
评论